容器网络比较复杂,目前主流的网络方案是以VXLAN为主的Overlay方案,关于VXLAN的理解,可以参考这篇文章《什么是VXLAN》。
这篇文章里,我们将容器网络分为单节点上的容器网络通信和跨节点网络通信两部分内容。
1.单Host容器网络
在单个host主机上Docker的网络模型有四种:None网络、Host网络、Bridge网络和User-defined网络。
None网络:单机版容器,没有网络,适用场景为无需联网的业务,比如生成随机码业务,用法为指定参数
--network=none。Host网络:连接到Host主机上,完全与主机共享网络,用法为指定参数
--network=host,由于直接共享主机网络无需转发,所以性能比桥接网络性能要好,但是要考虑到不能与主机端口冲突。Bridge网络:桥接网络,Docker的默认网络模型,通过桥转发网络流量,无需指定参数默认使用桥接网络。
Docker默认会生成一个
docker0的网桥,可看成一个交换机。1 2 3[root@ecs_lm_test ~]# brctl show bridge name bridge id STP enabled interfaces docker0 8000.024250df460d no在主机上查看
linux bridge桥信息,可见默认有一个docker0的桥,在没有容器启动的时候这个桥(理解成一个主机上的软交换机)上interfaces为空。启动一个busybox容器,不指定网络则默认使用网桥网络:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29[root@ecs_lm_test ~]# docker run -it busybox:v1.0 #启动一个busybox容器 / # ip a #在容器中查看IP地址 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 21: eth0@if22: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff inet 172.17.0.2/16 scope global eth0 valid_lft forever preferred_lft forever inet6 fe80::42:acff:fe11:2/64 scope link valid_lft forever preferred_lft forever / # [root@ecs_lm_test ~]# brctl show #在主机上查看linux网桥 bridge name bridge id STP enabled interfaces docker0 8000.024250df460d no vetha2b8732 [root@ecs_lm_test ~]# ifconfig docker0 #在主机上查看linux网桥配置IP docker0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 172.17.0.1 netmask 255.255.0.0 broadcast 0.0.0.0 inet6 fe80::42:50ff:fedf:460d prefixlen 64 scopeid 0x20<link> ether 02:42:50:df:46:0d txqueuelen 0 (Ethernet) RX packets 57 bytes 3884 (3.7 KiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 8 bytes 656 (656.0 B) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 [root@ecs_lm_test ~]#此时,网桥(Host主机上的一个软交换机)上生成一个接口
vetha2b8732,网桥的地址为172.17.0.1/16,容器内生成一个接口eth0@if22,地址为172.17.0.2/16。其详细拓扑类似于下图示。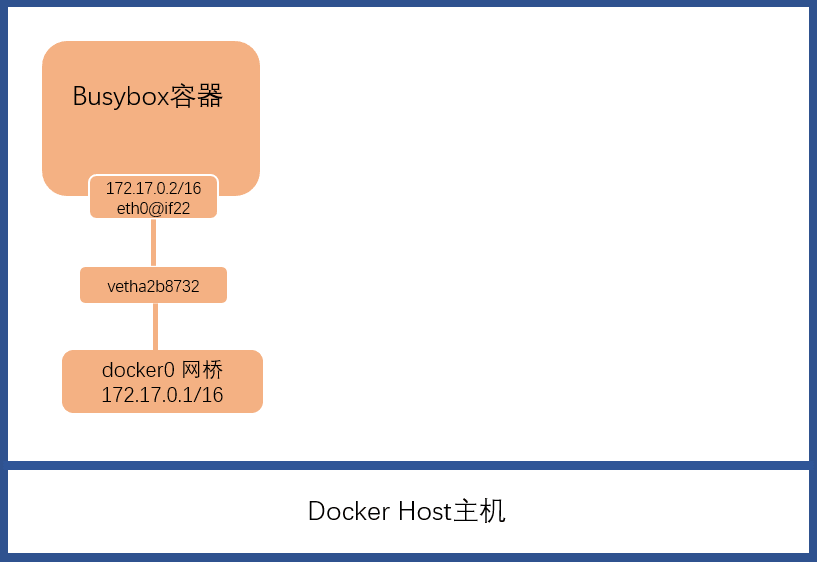
docker0网桥是在Docker安装完成后已经生成的,其默认地址为172.17.0.1/16。启动bubybox容器且默认使用桥接网络时,docker会给这个容器生成一个端口eth0,如上图中的eth0@if22,容器默认从172.17.0.0/16网段里分配一个IP给该端口,如本示例中分配的172.17.0.2/16;同时生成一个veth,如上图中的vetha2b8732。veth是一个键值对,连接网桥与容器端口。容器的网络流量均将通过这个网桥转给Host主机。User-defined网络:用户自定义网络,也是桥接网络的一种,通过桥转发。用法分两步:1)创建一个桥接网络network,如my_net;2)指定网络为自定义的桥接网络
--network=my_net。如下示例:1 2$sudo docker network create --driver bridge my_net #创建自定义桥接网络my_net $sudo docker run -it --network=my_net --name=busybox_2 busybox:v1.0 #创建一个容器busybox_2, 指定网络为my_net创建完网络以后可以查看一下自定义网络信息:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60[root@ecs_lm_test ~]# brctl show bridge name bridge id STP enabled interfaces br-af0983622432 8000.024250455fc5 no veth9c4e5f0 docker0 8000.024250df460d no vetha2b8732 [root@ecs_lm_test ~]# docker network ls NETWORK ID NAME DRIVER SCOPE dc6b5efa55b1 bridge bridge local bd6f8b541421 host host local 84dbdab42e7e my_net bridge local 8477f439c570 none null local [root@ecs_lm_test ~]# docker network inspect my_net [ { "Name": "my_net", "Id": "84dbdab42e7e1b57d304fa9f30cc0c2b1257af4a249d838ffd50516a4c28ee50", "Created": "2021-11-17T19:09:01.483500585+08:00", "Scope": "local", "Driver": "bridge", "EnableIPv6": false, "IPAM": { "Driver": "default", "Options": {}, "Config": [ { "Subnet": "172.18.0.0/16", "Gateway": "172.18.0.1" } ] }, "Internal": false, "Attachable": false, "Containers": {}, "Options": {}, "Labels": {} } ] [root@ecs_lm_test ~]# ifconfig br-af0983622432 br-af0983622432: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500 inet 172.18.0.1 netmask 255.255.0.0 broadcast 0.0.0.0 ether 02:42:50:45:5f:c5 txqueuelen 0 (Ethernet) RX packets 0 bytes 0 (0.0 B) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 0 bytes 0 (0.0 B) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0 [root@ecs_lm_test ~]# docker exec -it busybox_2 /bin/sh / # ip a 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 26: eth0@if27: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue state UP link/ether 02:42:ac:12:00:02 brd ff:ff:ff:ff:ff:ff inet 172.18.0.2/16 scope global eth0 valid_lft forever preferred_lft forever inet6 fe80::42:acff:fe12:2/64 scope link valid_lft forever preferred_lft forever / #可见创建了一个名为
br-af0983622432的、network名为my_net的桥接网络,其子网IP为172.18.0.0/16,网关IP为172.18.0.1/16,网关在网桥自身上。且Docker为容器busybox_2分配了一个接口eth0@if27对应IP为172.18.0.2/16;键值对为veth9c4e5f0,连接容器与网桥,其网络架构如下图示。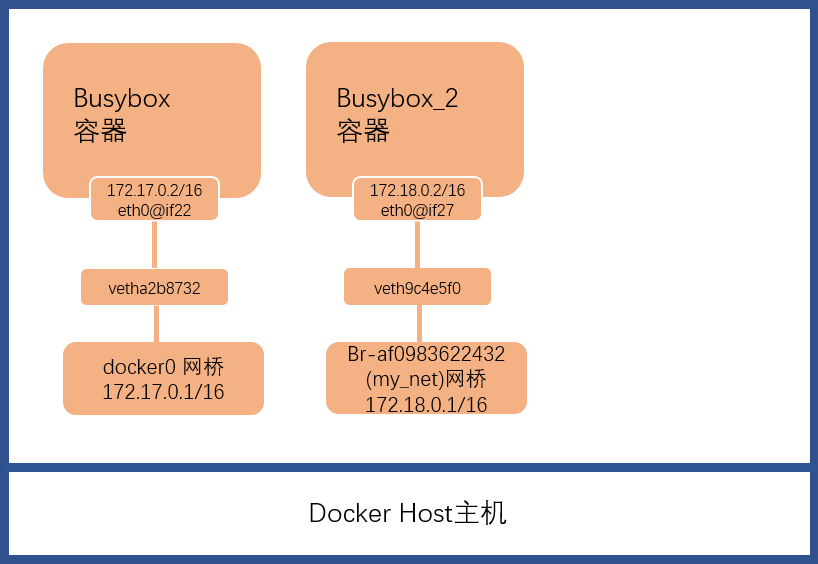
上面的示例中自定义网桥没有指定网段,默认使用
172.18.0.0/16网段,也可指定特定网段如172.19.0.0/16.1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63[root@ecs_lm_test ~]# docker network create --driver bridge --subnet 172.19.0.0/16 --gateway 172.19.0.1 my_net2 3182a1c4c328ae30c6a98cbb1148924585f6975531bc3a56718d9fcb8250f3b9 [root@ecs_lm_test ~]# docker network ls #可见生成了一个my_net2的网络 NETWORK ID NAME DRIVER SCOPE dc6b5efa55b1 bridge bridge local bd6f8b541421 host host local af0983622432 my_net bridge local 3182a1c4c328 my_net2 bridge local 8477f439c570 none null local [root@ecs_lm_test ~]# docker run -it --name=busybox_3 --network=my_net2 busybox:v1.0 #启动一个容器,指定网络为my_net2 / # ip a #在容器中查看其IP地址 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 29: eth0@if30: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue link/ether 02:42:ac:13:00:02 brd ff:ff:ff:ff:ff:ff inet 172.19.0.2/16 scope global eth0 valid_lft forever preferred_lft forever inet6 fe80::42:acff:fe13:2/64 scope link valid_lft forever preferred_lft forever / # [root@ecs_lm_test ~]# brctl show #在主机上查看可见生成了一个网桥名为br-3182a1c4c328,键值对veth9d6f750 bridge name bridge id STP enabled interfaces br-3182a1c4c328 8000.02421bd7d910 no veth9d6f750 br-af0983622432 8000.024250455fc5 no docker0 8000.024250df460d no vetha2b8732 [root@ecs_lm_test ~]# docker network inspect my_net2 #在主机上查看my_net2网络信息 [ { "Name": "my_net2", "Id": "3182a1c4c328ae30c6a98cbb1148924585f6975531bc3a56718d9fcb8250f3b9", "Created": "2021-11-18T09:38:28.214281939+08:00", "Scope": "local", "Driver": "bridge", "EnableIPv6": false, "IPAM": { "Driver": "default", "Options": {}, "Config": [ { "Subnet": "172.19.0.0/16", "Gateway": "172.19.0.1" } ] }, "Internal": false, "Attachable": false, "Containers": { "6d854882025fa02dd7e79b7a3258fd21e6ad38d9888fc414fcd79306b7920a44": { "Name": "busybox_3", "EndpointID": "a40fd9865bbcbbb72cc676c407f9b2ed5c496d7b1d56ccbb0dcbf1a9ed0c8a4a", "MacAddress": "02:42:ac:13:00:02", "IPv4Address": "172.19.0.2/16", "IPv6Address": "" } }, "Options": {}, "Labels": {} } ]可见在主机上创建了一个
my_net2的自定义网络,网桥名为my_net2,指定容器以该网桥启动后,Docker生成了一个键值对veth9d6f750,整个网络的地址段为172.19.0.0/16,整体网络架构如下图示。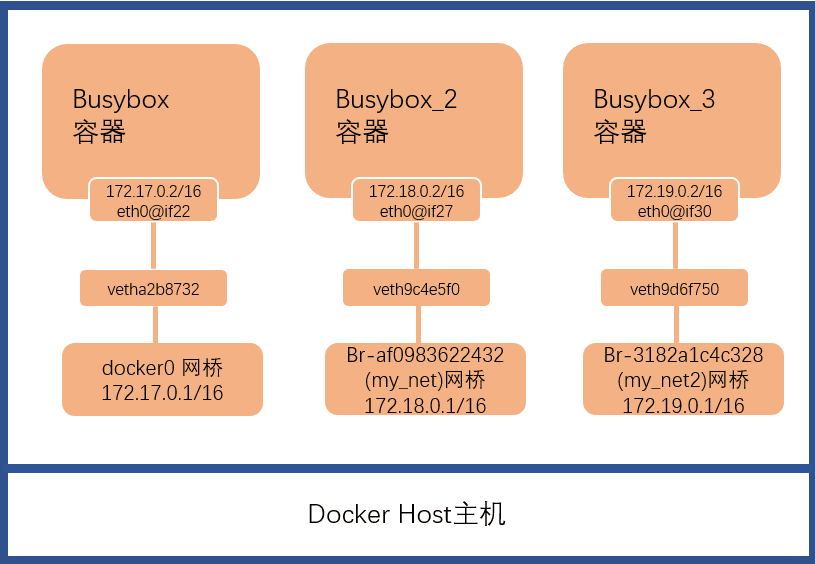
显然这三个容器不在同一个网桥上是互相隔离,无法互通的,如果需要互通怎么办,比如讲容器2与容器3打通网络?可为容器
busybox_2再加一个my_net2的网卡即可,可使用命令docker network connect [network] [container name/id]将容器2连接到网桥2上来。1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28[root@ecs_lm_test ~]# docker network connect my_net2 busybox_2 [root@ecs_lm_test ~]# docker exec -it busybox_2 /bin/sh / # ip a 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 33: eth0@if34: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue link/ether 02:42:ac:12:00:02 brd ff:ff:ff:ff:ff:ff inet 172.18.0.2/16 scope global eth0 valid_lft forever preferred_lft forever inet6 fe80::42:acff:fe12:2/64 scope link valid_lft forever preferred_lft forever 35: eth1@if36: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue link/ether 02:42:ac:13:00:03 brd ff:ff:ff:ff:ff:ff inet 172.19.0.3/16 scope global eth1 valid_lft forever preferred_lft forever inet6 fe80::42:acff:fe13:3/64 scope link valid_lft forever preferred_lft forever [root@ecs_lm_test ~]# brctl show bridge name bridge id STP enabled interfaces br-3182a1c4c328 8000.02421bd7d910 no veth6f2fed5 veth9d6f750 br-81a7cff59d14 8000.0242576559e7 no vethecf3979 docker0 8000.024250df460d no vetha2b8732这里可见已经新生产一个veth键值对,容器端的端口为
eth1@if36,地址为172.19.0.3/16。此时的网络架构如下: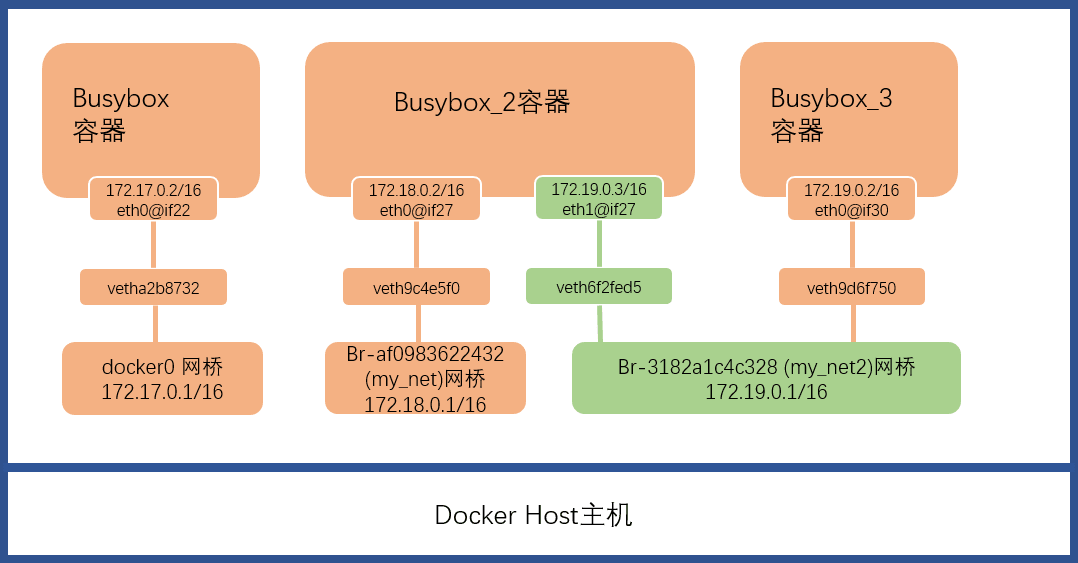
从容器
busybox_2中往容器busybox_3做ping测: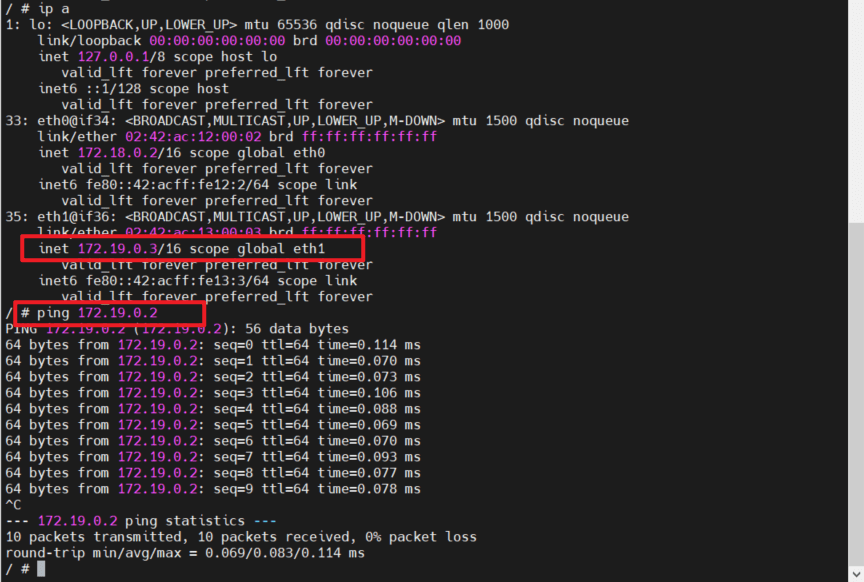
2.容器通信
容器可通过IP,DNS,Joined容器三种方式进行通信。
IP通信:IP只要能够互通即可,如上面busybox_2与busybox_3之间使用IP进行通信。
DNS:在使用了
user-defined的桥接网络的容器,可以直接使用容器名进行通信。1 2 3 4 5[root@ecs_lm_test ~]# docker exec -it busybox_2 sh / # ping busybox_3 PING busybox_3 (172.19.0.2): 56 data bytes 64 bytes from 172.19.0.2: seq=0 ttl=64 time=0.068 ms 64 bytes from 172.19.0.2: seq=1 ttl=64 time=0.097 ms需要注意的是,这里只适用于
user-defined的桥接网络,默认桥接网络不行。Joined容器:即多个容器共享一个网络栈,共享MAC,IP等。可使用
--network=container:[已有容器name/ID]来指定新容器,如:1 2 3 4 5 6 7 8 9 10 11 12 13 14 15[root@ecs_lm_test ~]#docker run -it --name=busybox_4 --network=container:busybox_3 busybox:v1.0 / # ip a 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 29: eth0@if30: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue link/ether 02:42:ac:13:00:02 brd ff:ff:ff:ff:ff:ff inet 172.19.0.2/16 scope global eth0 valid_lft forever preferred_lft forever inet6 fe80::42:acff:fe13:2/64 scope link valid_lft forever preferred_lft forever / #可见容器
busybox_4与容器busybox_3的网络是完全一致的。
3.容器与外部网络互通
这里分两部分来看,首先是容器访问外部网络,其次是外部网络访问容器。
容器访问外部网络:容器网络与外部互通以后,容器可以访问外部,这里网络类型其实只有两种:
- Host类型:容器直接通过Host转发流量。
- Bridge类型:无论是Docker默认网络类型还是自定义类型,均是桥接网络,其访问外部网络一般分为四个步骤:
- 1)容器发起外部访问
- 2)网桥(如默认的docker0网络和自定义的bridge网络)转发给主机host
- 3)主机host通过NAT转换源地址为host本机地址
- 4)host主机发起外部访问
外部网络访问容器:外部网络访问容器指的是在IP可达之后,容器提供对外服务,外部通过IP网络访问该服务,如容器提供一个Nginx服务,外部通过IP访问到该服务。在对外服务中,需要将服务端口暴露隐射至主机端口,主要包含以下几个步骤:
- 1)容器中提供对外服务,对外暴露服务端口xxx,如8090
- 2)启动容器时将主机端口8091绑定到容器端口8090,
docker run -p 8091:8090 [其他参数] - 3)docker-proxy进程会监听主机端口8091
- 4)当外部访问到主机的8091端口时,主机转发至容器8090端口
- 5)容器对外服务端口接收到流量后服务程序开始处理
4.跨Host网络
Docker跨Host有包括原生的overlay和macvlan方案和多种第三方方案,如下图所示。
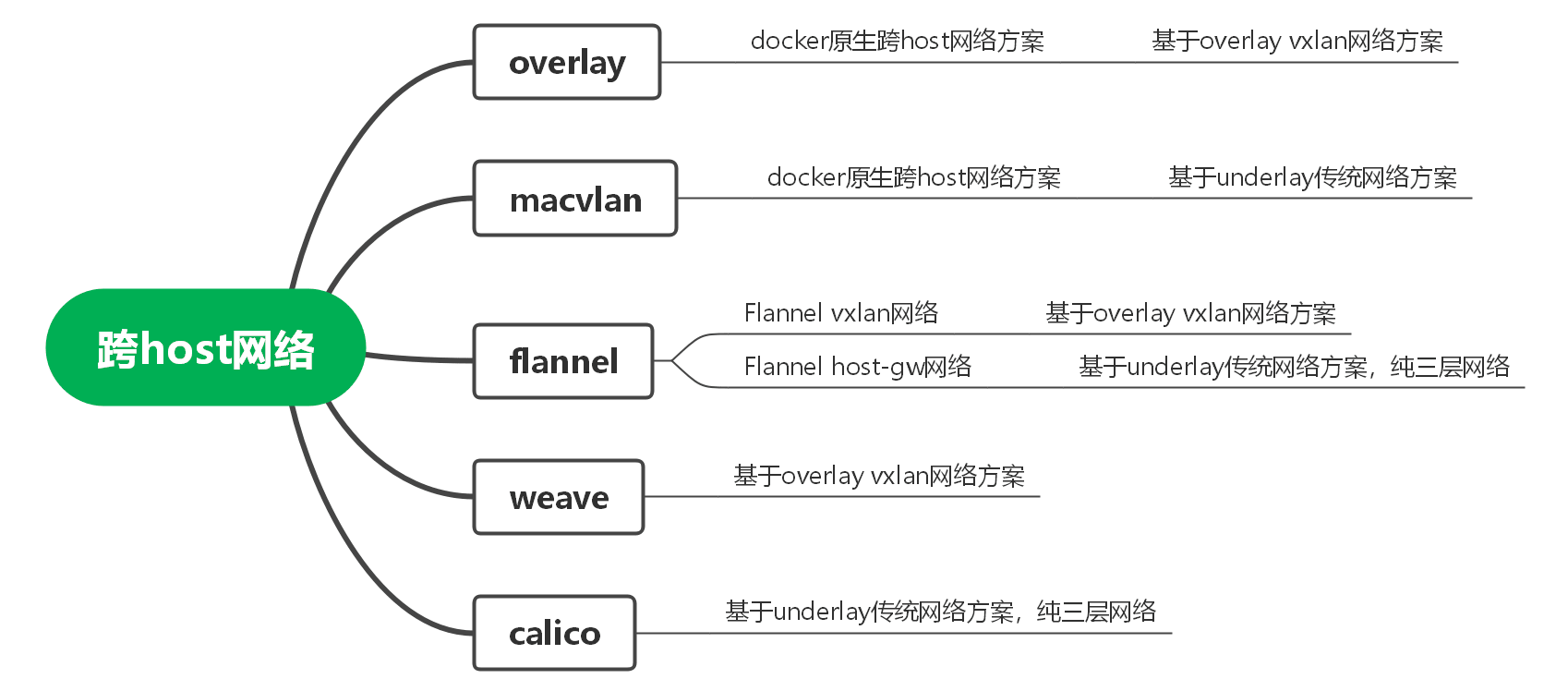
其中原生方案中用的较多的是overlay方案,其基本原理是在本端隧道起点VTEP 1将二层网络数据封装在三层UDP数据中通过隧道技术传输,在对端隧道终点VTEP 2上解封装,通过三层路由来打通二层网络,与GRE隧道类似,形成大二层网络。
原生MACVLAN方案本质就是传统三层网络互通方案,性能比overlay要好,但是局限于二层网络VLAN的规模。
除Docker原生网络方案以外,还有三个常见的第三方网络方案flannel、weave和calico。这里重点记录一下前两种flannel和weave方案。
4.1 flannel方案
flannel是CoreOS公司开发的跨主机通信网络解决方案,它会为每个host分配一个subnet,容器从这个subnet中获取IP地址,这个IP地址在各个host主机组成的集群中是全局唯一的,其框架如下:
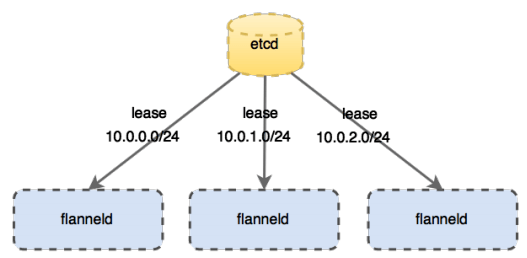
- 每个节点上有一个叫
flanneld的agent,负责为每个主机分配和管理子网; - 全局的网络配置存储
etcd负责存储主机容器子网的映射关系; - 数据包在主机之间发展是由
backend来实现的,常见的backend有VXLAN和host-gw两种模式。
4.1.1 flannel数据转发VXLAN模式
关于VXLAN的本质用一句话概括,就是将三层网络数据封装在虚拟二层网络中,通过二层互通实现三层网络不同网段IP互通,同时突破了同一个VLAN只有2049个子网的限制,VXLAN使用VNI(24 bit)来标识VXLAN网络,故而有(2^24)个子网。
下面转自水立方在掘金博文:《Flannel的两种模式解析(VXLAN、host-gw)》
VXLAN模式是Flannel默认和推荐的模式,使用VXLAN模式时,它会为每个节点分配一个24位子网 。flanneld会在宿主机host上创建一个 VTEP 设备(flannel.1)和一个网桥cni0。(flannel.1)就是VXLAN隧道的起/始点,VNI=1,实现对VXLAN报文的解封装。
来看看跨节点Node1和Node2之间的容器互通式如何通信的?
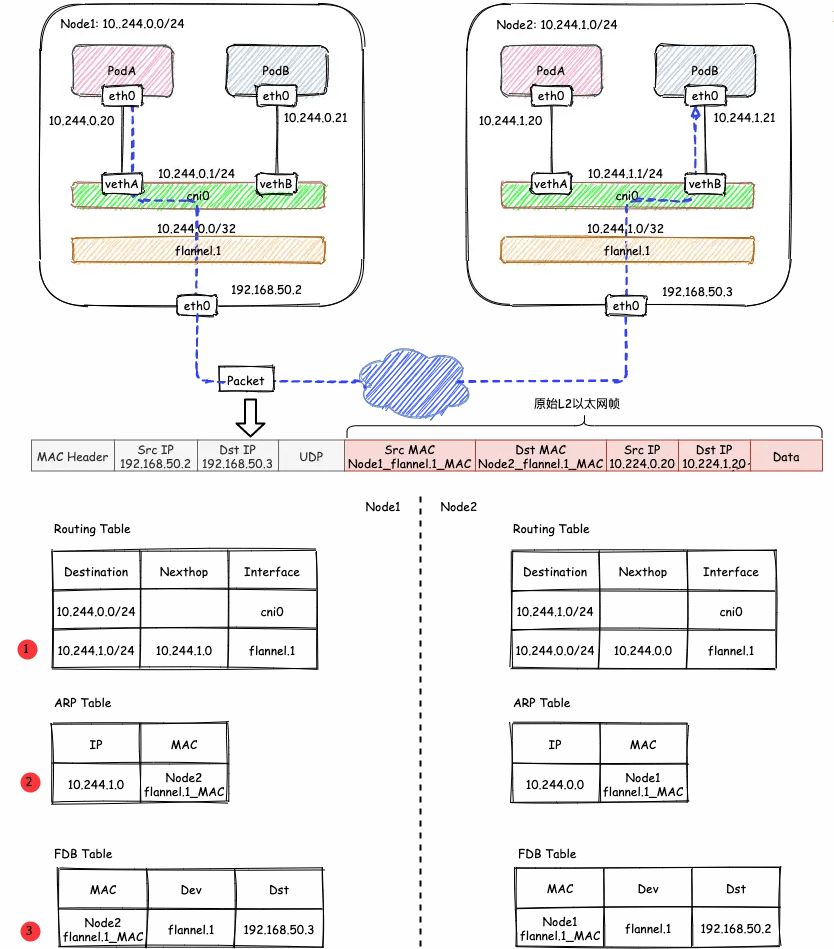
- 发送端Node1:在Node1的PodA(假设含一个容器)中发起对Node2的PodB(假设含一个容器)的ping测
ping 10.244.1.21,ICMP报文经过cni0网桥后交由flannel.1设备处理。flannel.1设备是一个VXLAN类型的设备,负责VXLAN封包解包。 因此,在发送端,flannel.1将原始L2报文封装成VXLAN UDP报文,然后从eth0发送。 - 接收端:Node2收到UDP报文,发现是一个VXLAN类型报文,交由
flannel.1进行解包。根据解包后得到的原始报文中的目的IP,将原始报文经由cni0网桥发送给PodB。
- 哪些IP要交由
flannel.1处理
flanneld 从 etcd 中可以获取所有节点的子网情况,以此为依据为各节点配置路由,将属于非本节点的子网IP都路由到 flannel.1 处理,本节点的子网路由到 cni0 网桥处理。
| |
如果节点信息有变化, flanneld 也会从etcd中同步更新路由信息。
flannel.1的封包过程
VXLAN的封包是将二层以太网帧封装到四层UDP报文中的过程。
原始L2帧
要生成原始的L2帧,
flannel.1需要得知:内层源/目的IP地址
内层源/目的MAC地址
内层的源/目的IP地址是已知的,即为PodA/PodB的PodIP,在图例中,分别为10.224.0.20和10.224.1.20。 内层源/目的MAC地址要结合路由表和ARP表来获取。根据路由表①得知:
- 1)下一跳地址是10.224.1.0,关联ARP表②,得到下一跳的MAC地址,也就是目的MAC地址:
Node2_flannel.1_MAC; - 2)报文要从
flannel.1虚拟网卡发出,因此源MAC地址为flannel.1的MAC地址。
要注意的是,这里ARP表的表项②并不是通过ARP学习得到的,而是
flanneld预先为每个节点设置好的,由flanneld负责维护,没有过期时间。1 2 3# 查看ARP表 [root@Node1 ~]# ip n | grep flannel.1 10.244.1.0 dev flannel.1 lladdr ba:74:f9:db:69:c1 PERMANENT # PERMANENT 表示永不过期有了上面的信息,
flannel.1就可以构造出内层的2层以太网帧:
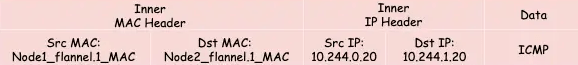
外层VXLAN UDP报文
要将原始L2帧封装成VXLAN UDP报文,
flannel.1还需要填充源/目的IP地址。我们知道VTEP是VXLAN隧道的起点或终点。因此,目的IP地址即为对端VTEP的IP地址,通过FDB表获取。在FDB表③中,dst字段表示的即为VXLAN隧道目的端点(对端VTEP)的IP地址,也就是VXLAN DUP报文的目的IP地址。FDB表也是由flanneld在每个节点上预设并负责维护的。FDB表(Forwarding database)用于保存二层设备中MAC地址和端口的关联关系,就像交换机中的MAC地址表一样。在二层设备转发二层以太网帧时,根据FDB表项来找到对应的端口。例如cni0网桥上连接了很多veth pair网卡,当网桥要将以太网帧转发给Pod时,FDB表根据Pod网卡的MAC地址查询FDB表,就能找到其对应的veth网卡,从而实现联通。
可以使用
bridge fdb show查看FDB表:1 2[root@Node1 ~]# bridge fdb show | grep flannel.1 ba:74:f9:db:69:c1 dev flannel.1 dst 192.168.50.3 self permanent源IP地址信息来自于
flannel.1网卡设置本身,根据local 192.168.50.2可以得知源IP地址为192.168.50.2。1 2 3 4 5 6 7 8[root@Node1 ~]# ip -d a show flannel.1 6: flannel.1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1450 qdisc noqueue state UNKNOWN group default link/ether 32:02:78:2f:02:cb brd ff:ff:ff:ff:ff:ff promiscuity 0 vxlan id 1 local 192.168.50.2 dev eth0 srcport 0 0 dstport 8472 nolearning ageing 300 noudpcsum noudp6zerocsumtx noudp6zerocsumrx numtxqueues 1 numrxqueues 1 gso_max_size 65536 gso_max_segs 65535 inet 10.244.0.0/32 brd 10.244.0.0 scope global flannel.1 valid_lft forever preferred_lft forever inet6 fe80::3002:78ff:fe2f:2cb/64 scope link valid_lft forever preferred_lft forever至此,
flannel.1已经得到了所有完成VXLAN封包所需的信息,最终通过eth0发送一个VXLAN UDP报文: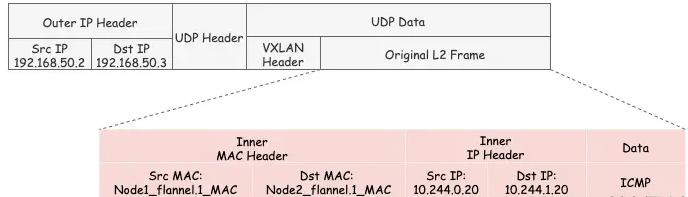
即:把原始L2数据包封装在了UDP报文中,外层IP可二层直通,二层互通以后再VTEP端点进行VXLAN解封装后进行交互。
Flannel的VXLAN模式通过静态配置路由表,ARP表和FDB表的信息,结合VXLAN虚拟网卡
flannel.1,实现了所有容器同属一个大二层网络的VXLAN网络模型。
4.1.2 Flannel数据转发之host-gw模式
在上述的VXLAN的示例中,Node1和Node2其实是同一物理宿主机中的两台使用桥接模式的VM虚机,也就是说它们在一个二层网络中。在二层网络互通的情况下,直接配置节点的三层路由即可互通,不需要使用VXLAN隧道。要使用host-gw模式,在Kubernets中需要修改 ConfigMap kube-flannel-cfg ,将 Backend.Type 从vxlan改为host-gw,然后重启所有kube-flannel Pod即可:
| |
如果是docker直接使用Flannel,也需要修改类似的配置,不过是在文件flannel-config.json中直接修改,然后更新etcd数据库。
host-gw模式下的通信过程如下图所示:
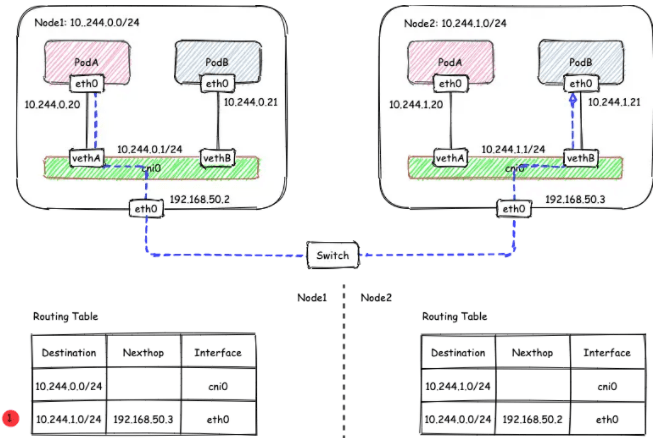
在host-gw模式下,由于不涉及VXLAN的封包解包,不再需要flannel.1虚机网卡。 flanneld 负责为各节点设置路由 ,将对应节点Pod子网的下一跳地址指向对应的节点的IP,如图中路由表①所示。
| |
由于没有封包解包带来的消耗,host-gw是性能最好的。不过一般在云环境下,都不支持使用host-gw的模式,在私有化部署的场景下,可以考虑。
4.2 weave方案
weave创建的虚拟网络可以将部署在多个机器的容器连接起来。对容器来说,weave就像一个巨大的以太网交换机,所有容器都会接入这个交换机,容器可以直接通信,无需NAT和端口映射。
默认配置下,weave使用一个大subnet(10.32.0.0/12),所有主机的容器都从这个地址空间中分配IP,因为同属一个subnet,weave网络中的所有容器可以直接通信。
参考《每天5分钟玩转docker技术》的weave网络章节,先做个实验跑起来。
安装完weave后在 host1中运行容器 busybox_weave:
| |
执行 eval $(weave env) 的作用是将后续的 docker 命令发给 weave proxy 处理,在此基础上的容器使用的网络模型就是weave。如果要恢复之前的环境,可执行 eval $(weave env --restore)。查看一下当前容器网络环境:
| |
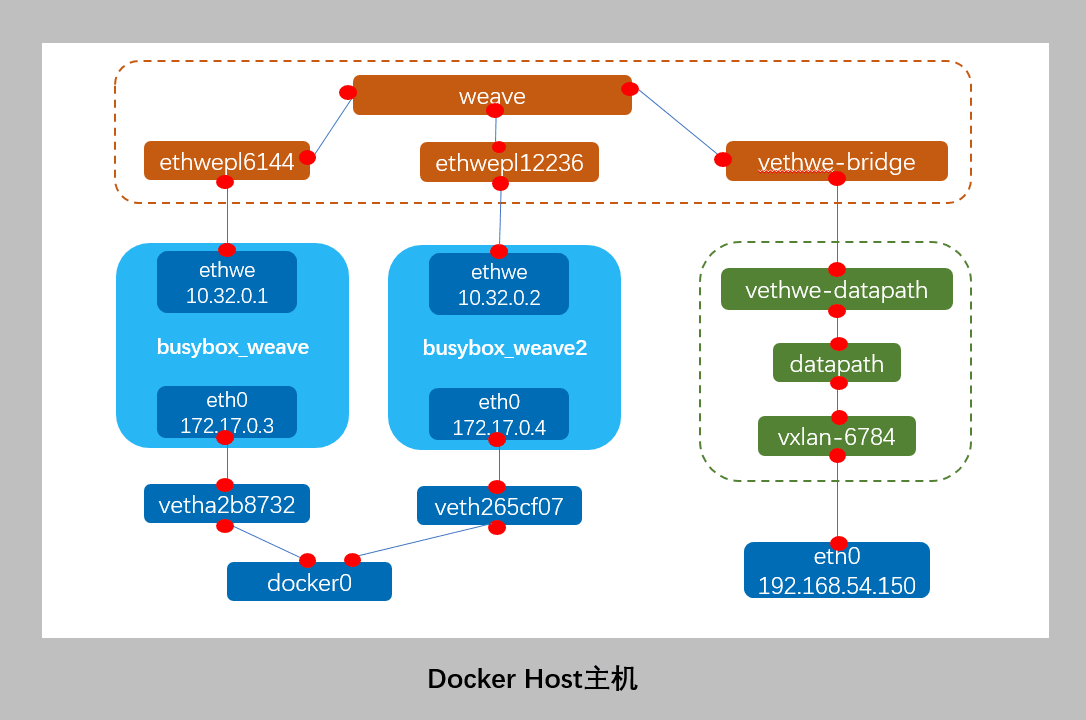
可见容器生成了,eth0@if46和ethwe@if48,且除了默认docker0网桥以外,多出了weave网桥。其网络模型如下截图示:
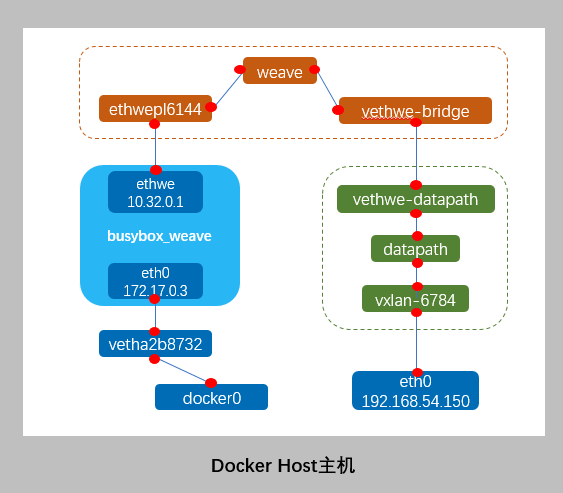
weave 网络包含两个虚拟交换机:Linux bridge weave 和 Open vSwitch datapath,veth pair vethwe-bridge 和 vethwe-datapath 将二者连接在一起。
weave 和 datapath 分工不同,weave 负责将容器接入 weave 网络,datapath 负责在主机间 VxLAN 隧道中并收发数据。
① vethwe-bridge 与 vethwe-datapath 是 veth pair,连接weave网络与datapath网络。
② vethwe-datapath 的父设备(master)是 datapath。
③ datapath 是一个 openvswitch。
④ vxlan-6784 是 vxlan interface,其 master 也是 datapath,weave 主机间是通过 VxLAN 通信的,就是VTEP起始端点,通过主机eth0转发流量。
再新增一个容器busybox_weave2:
| |
可见docker0网桥上新生成了接口veth265cf07,weave网桥上新生成了vethwepl12236,对应组br网架构如下图:
从容器bubybox_weave往容器bubybox_weave2和Host主机端口eth0做ping测试试:
| |
从容器1分别去对容器2和主机端口做ping测,结果都能ping通,因为weave和datapath已经将这部分网络打通。
上面的用例是在同一个主机上的多个容器,如果是跨Host主机之间的容器,weave是如何处理的呢?
多Host主机之间通过Weave通信
weave在多主机之间通过vxlan传输数据,VTEP起始点分别由主机的datapath这个openVSwith生成,对应vxlan-xxx端口,通过一个实例理解一下。
加入weave网络的主机必须是同一个二层互通的网络,上面的主机是在云上建立的,第一个host主机VPC子网是192.168.32.0/19,再新建一个主机加入到相同子网中。两个主机的IP地址分别为192.168.54.150/19和192.168.54.21/19。
host2必须指定host1的IP 192.168.54.150,这样host1和host2才能加入到同一个weave网络。
1 2 3 4 5 6 7 8 9[root@ecs_lm_test2 myimages]# eval $(weave env) [root@ecs_lm_test2 myimages]# weave launch 195.168.54.150 cannot locate running docker daemon Warning: unable to detect proxy TLS configuration. To enable TLS, launch the proxy with 'weave launch' and supply TLS options. To suppress this warning, supply the '--no-detect-tls' option. d7643e59716e4a6f861f7e89a9819f7d76640474604dbd087e62b8f413758618 [root@ecs_lm_test2 myimages]# brctl show bridge name bridge id STP enabled interfaces docker0 8000.02426891e1ee no weave 8000.625ddc22c535 no vethwe-bridge可见主机已经生成一个weave网桥,和一个接口
vethwe-bridge。创建一个容器加入weave网络。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53[root@ecs_lm_test2 ~]# docker run --name busybox_weave_host2_1 -it -d busybox:v1.0 1355472f761a5a50400522602c29eb1e60e81d5923800f200bf1fd4d7651722e [root@ecs_lm_test2 ~]# [root@ecs_lm_test2 ~]# docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 1355472f761a busybox:v1.0 "sh" 25 seconds ago Up 24 seconds busybox_weave_host2_1 d7643e59716e weaveworks/weave:latest "/home/weave/weave..." 14 minutes ago Up 14 minutes weave c0799cfead90 weaveworks/weaveexec:latest "data-only" 14 minutes ago Created weavevolumes-latest a6ce55a36584 weaveworks/weavedb:latest "data-only" 14 minutes ago Created weavedb [root@ecs_lm_test2 ~]# brctl show bridge name bridge id STP enabled interfaces docker0 8000.02426891e1ee no veth9b93012 weave 8000.625ddc22c535 no vethwe-bridge vethwepl23496 [root@ecs_lm_test2 ~]# docker exec -it busybox_weave_host2_1 ip a 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue qlen 1000 link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo valid_lft forever preferred_lft forever inet6 ::1/128 scope host valid_lft forever preferred_lft forever 24: eth0@if25: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1500 qdisc noqueue link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff inet 172.17.0.2/16 scope global eth0 valid_lft forever preferred_lft forever inet6 fe80::42:acff:fe11:2/64 scope link valid_lft forever preferred_lft forever 26: ethwe@if27: <BROADCAST,MULTICAST,UP,LOWER_UP,M-DOWN> mtu 1376 qdisc noqueue link/ether c2:62:6f:e0:5f:c3 brd ff:ff:ff:ff:ff:ff inet 10.44.0.0/12 brd 10.47.255.255 scope global ethwe valid_lft forever preferred_lft forever inet6 fe80::c062:6fff:fee0:5fc3/64 scope link valid_lft forever preferred_lft forever [root@ecs_lm_test2 ~]# ip a |grep eth0 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP group default qlen 1000 inet 192.168.54.21/19 brd 192.168.63.255 scope global noprefixroute dynamic eth0 [root@ecs_lm_test2 ~]# [root@ecs_lm_test2 ~]# docker exec -it busybox_weave_host2_1 ping 10.32.0.1 PING 10.32.0.1 (10.32.0.1): 56 data bytes 64 bytes from 10.32.0.1: seq=0 ttl=64 time=1.611 ms 64 bytes from 10.32.0.1: seq=1 ttl=64 time=0.669 ms ^C --- 10.32.0.1 ping statistics --- 2 packets transmitted, 2 packets received, 0% packet loss round-trip min/avg/max = 0.669/1.140/1.611 ms [root@ecs_lm_test2 ~]# docker exec -it busybox_weave_host2_1 ping 10.32.0.2 PING 10.32.0.2 (10.32.0.2): 56 data bytes 64 bytes from 10.32.0.2: seq=0 ttl=64 time=1.496 ms ^C --- 10.32.0.2 ping statistics --- 1 packets transmitted, 1 packets received, 0% packet loss round-trip min/avg/max = 1.496/1.496/1.496 ms [root@ecs_lm_test2 ~]#主机2容器
busybox_weave_host2_1分配到的地址为10.44.0.0/12,跟主机1的容器地址10.32.0.1/12同属于同一个子网段10.32.0.1/12-10.47.255.255/12,通过host1与host2直接的vxlan隧道,三个容器逻辑上在同一个大二层网络中,所以能够互通,对应网络架构图如下。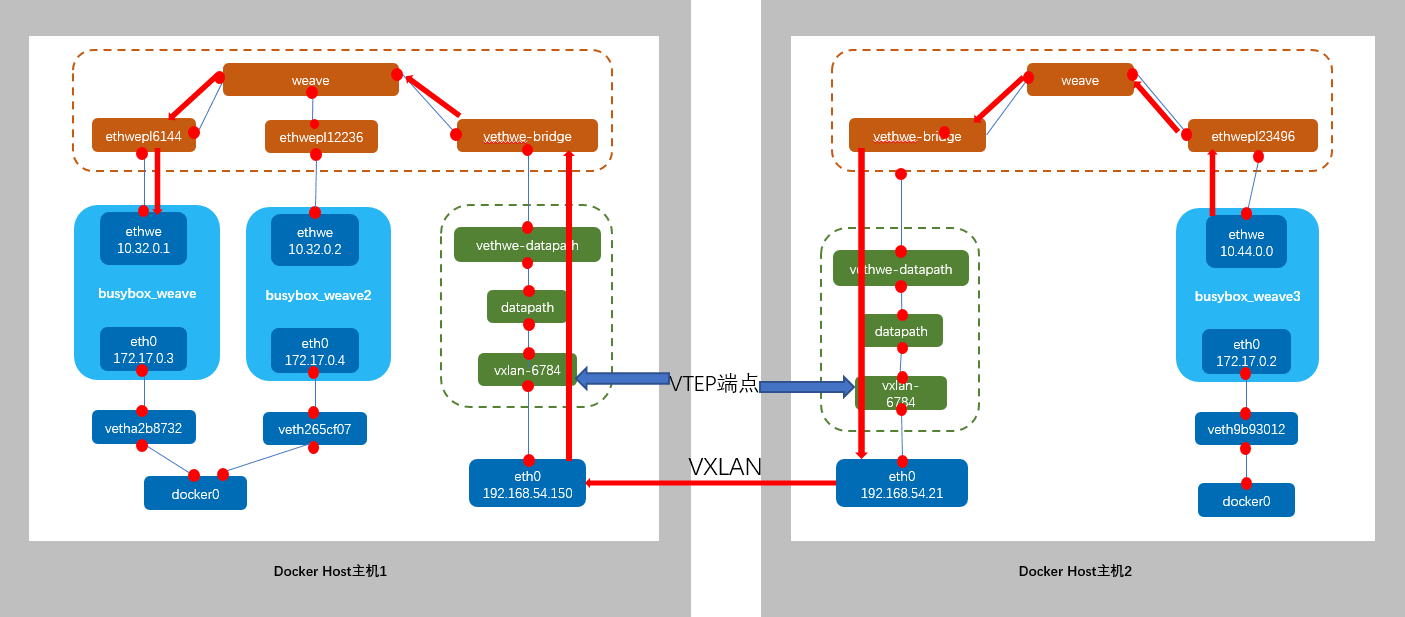
Weave网络隔离
从上面的几个例子中可见加入到同一个weave网络的所有容器默认可以互通,如果想要进行网络隔离呢?只需在启动容器时通过命令-e WEAVE_CIDR=net:[ip-subnet]指定非默认subnet即可,这样的话容器不会从默认的10.32.0.1/12中分配地址,如10.32.2.0/24子网不跟10.32.0.1/12一个网段,给容器指定子subnet:
| |
参考文档
《Flannel的两种模式解析(VXLAN、host-gw)》
全文完。
